

2020年4月8日
Jerry
10564
2020年4月8日
C# 使用httpwebrequest抓取一个网页,返回一直乱码?修改编码格式也没有解决,看看怎么搞!
问题:
C# httpwebrequest 抓取网页返回乱码。
代码:
public void GetHtml()
{
try
{
string url = "http://kaijiang.500.com";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream;
StreamReader sr;
stream = response.GetResponseStream();
sr = new StreamReader(stream, Encoding.UTF8);
string strHtml = sr.ReadToEnd();
stream.Close();
sr.Close();
Console.WriteLine(strHtml);
}
catch (WebException e)
{
e.StackTrace.ToString();
return;
}
}
返回乱码:
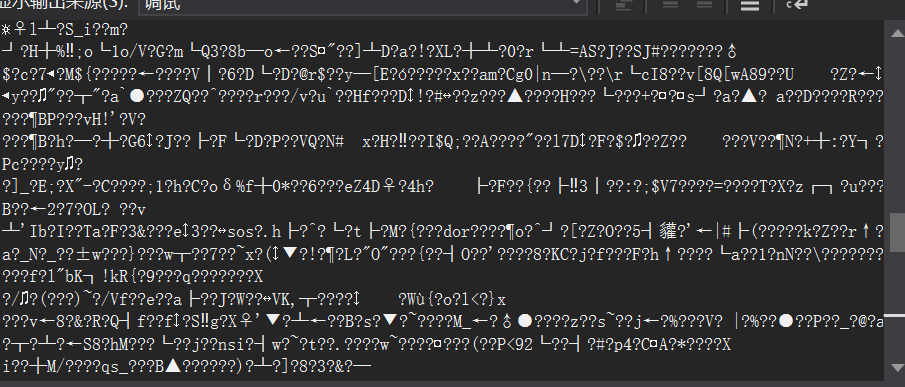
开始解决:
1、那肯定是编码不对啊,改一下就完了呗。
看下网页的编码,是 gb2312

而代码里面的编码是UTF8,于是把编码改成了gb2312:
sr = new StreamReader(stream, Encoding.GetEncoding("gb2312"));
然而并没有解决啊!!!!!换成了另外一种乱码

接下来就开始尝试各种编码。。。
。。。。
。。。。
都没有解决,最后搜到了一种处理方法,直接上代码:
public void GetHtml()
{
try
{
string url = "http://kaijiang.500.com";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream;
StreamReader sr;
if (response.ContentEncoding == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
sr = new StreamReader(stream, Encoding.GetEncoding("gb2312"));
}
else
{
stream = response.GetResponseStream();
sr = new StreamReader(stream, Encoding.UTF8);
}
string strHtml = sr.ReadToEnd();
stream.Close();
sr.Close();
Console.WriteLine(strHtml);
}
catch (WebException e)
{
e.StackTrace.ToString();
return;
}
}
原创文章,转载请注明出处:
https://jerrycoding.com/article/csharp-encoding
微信

支付宝

