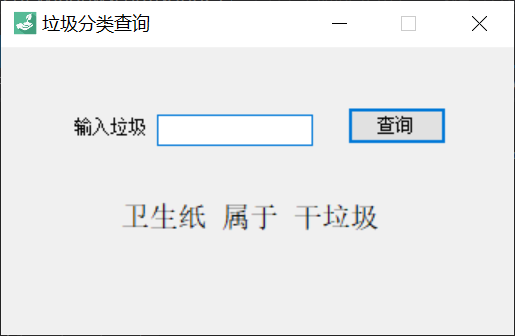
C# winform 实现垃圾分类爬虫小程序,查询输入的物品具体属于什么垃圾。
好久没有写代码了,仿佛人生没有了方向。python做爬虫很简单,但是界面就比较费劲了。而且python打包成exe也好大的包,于是又想研究研究c#。反正也是一天天的东搞西搞。
一、数据来源
博主投机取巧,数据来自网站:https://lajifenleiapp.com/

随便查询一个垃圾,发现网址规律都是这种:
https://lajifenleiapp.com/sk/卫生纸
https://lajifenleiapp.com/sk/黄瓜
https://lajifenleiapp.com/sk/塑料
于是,一切就变得简单了,我们只需要构造url,访问解析结果就OK了。
二、构造界面
新建一个c# winform程序,构造成下图样式,编辑框接收输入信息,点击查询按钮进行网页爬取、信息解析以及显示。
远程请求使用webrequest完成,下面是一个简单的get请求的例子:
//Get
public string GetContent(string uri, Encoding coding)
{
//Get请求中请求参数等直接拼接在url中
WebRequest request = WebRequest.Create(uri);
//返回对Internet请求的响应
WebResponse resp = request.GetResponse();
//从网络资源中返回数据流
Stream stream = resp.GetResponseStream();
StreamReader sr = new StreamReader(stream, coding);
//将数据流转换文字符串
string result = sr.ReadToEnd();
//关闭流数据
stream.Close();
sr.Close();
return result;
}
于是,我们只需要根据输入的垃圾信息构造出链接即可:
string url = "http://lajifenleiapp.com/sk/" + textBox1.Text;
string str = GetContent(url, Encoding.UTF8);
使用 Console.WriteLine(str); 将返回的网页信息打印出来:没错,就是一个完整的html,具体内容和网页源代码看到的是一样的。

找到其中最关键的一句,
<div style="width:fit-content; display:inline-block;border: 1.3px dashed #3c85ee;border-radius: 8px;padding:0px 20px;"><h1><span style="color:#D42121;">卫生纸</span><span style="color:#FBbC28;"> 属于 </span><span style="#2e2a2b">干垃圾</span></h1></div>
接下来的任务就是把每个返回网页的这一段解析就OK了。
三、结果解析
关于解析,有很多种方法,正则啊什么乱七八糟的,这里用别人写好的简单轮子 HtmlAgilityPack 解析。
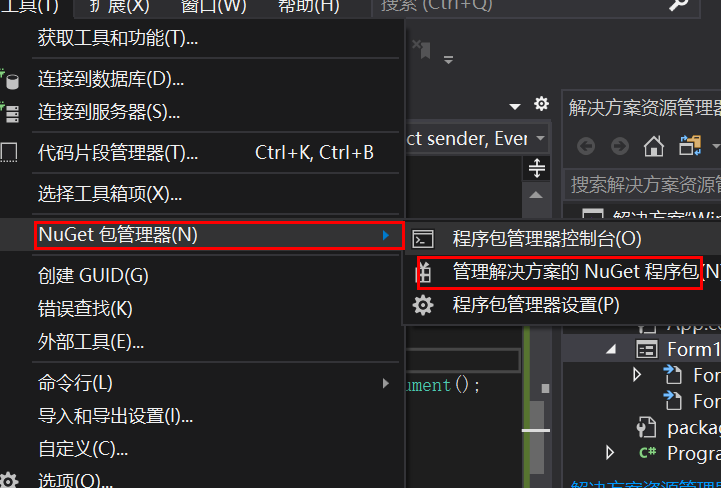
首先在项目中添加 HtmlAgilityPack 包,vs2019 点击工具--> nuget包管理-->管理程序包,输入 HtmlAgilityPack 安装到该项目即可。

然后开始编写代码,
//创建对象
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
//加载html
doc.LoadHtml(str);
HtmlAgilityPack.HtmlNode htmlnode = doc.DocumentNode.SelectSingleNode("/html/body/div/div[4]/div[2]/div[3]/h1");
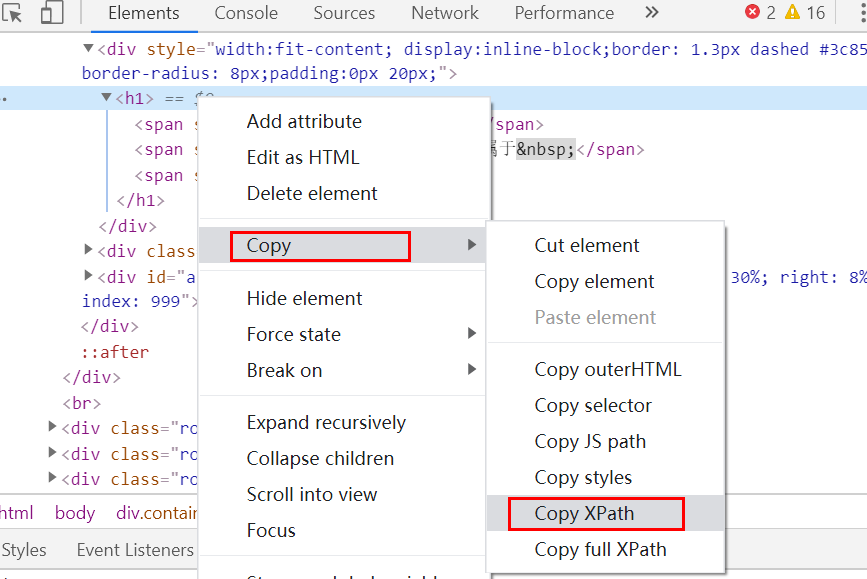
根据 xpath 来获取带有结果信息的节点。xpath可以通过下面这个简单的方法复制到:最后得到的就是“/html/body/div/div[4]/div[2]/div[3]/h1”
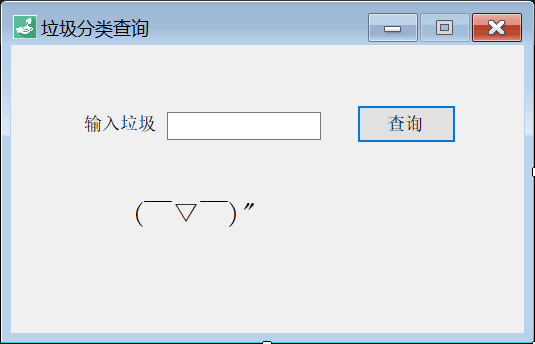
于是乎,轻松就可以得到这个节点,怎么取其中的信息也就很easy了。这里还要加个判断,因为可能输入的物品比较奇葩,万一搜索不到结果呢,这个节点会是null哦!
string s;
if (htmlnode != null)
{
s = htmlnode.InnerText;
s = s.Replace(" ", " ");
}
else
{
s = "未查询到相关信息!";
}
Console.WriteLine(s);
label3.Text = s;
最后的实现就是这样了!