

OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
利用OCR api 可以轻松实现图片中文字的提取。目前比较成熟的 OCR api 有百度、搜狗、有道等。这里玩玩百度,简单的几行代码就可以对接百度,从而实现简单的文字提取。关于百度OCR的介绍看 官网。
一、创建应用
需要在官网上创建一个自己的应用,填写应用名称、类型、应用描述等就可以。

创建成功后在应用列表可以看到刚刚创建的,我们过会需要这里面的两个key
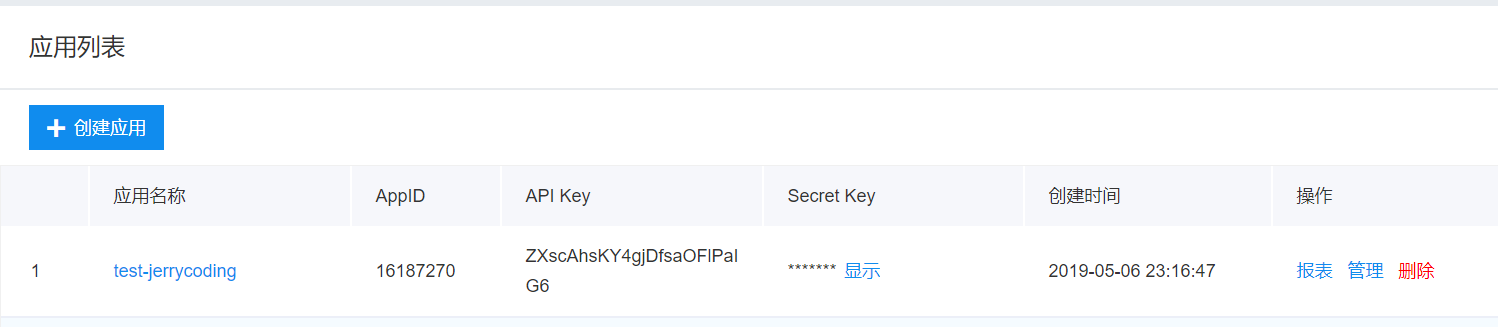
二、获取 access_token
查看 提供的API文档,可以看到在调用api识别接口之前,需要获取一个access_token。获取方式也很简单,对一个固定的url传入我们应用的 apikey 和 secretkey 即可。


一个简单的获取 token 的函数便诞生了:
def get_token():
token_url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=xxxxxxxxxxxxxx&client_secret=yyyyyyyyyyyyyyyyyyyyyyyy'
try:
token_res = requests.get(token_url)
except:
return 'error'
else:
try:
print(token_res.text)
res = token_res.json()["access_token"]
except:
return 'error'
else:
return res
服务器返回的JSON文本参数如下:我们取其中的 access_token 字段即可。
- access_token: 要获取的Access Token;
- expires_in: Access Token的有效期(秒为单位,一般为1个月);
- 其他参数忽略,暂时不用;
三、获取图片64编码
查看api文档,通用文本识别需要我们将图片的base64编码传入,于是又诞生了获取图片编码的函数。
def get_pic64():
try:
with open ('./test.png','rb') as pic:
img64 = base64.b64encode(pic.read())
except:
return 'error'
else:
return img64
四、传入百度api解析
简单的请求参数如下:
HTTP 方法:POST
请求URL: https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic
URL参数:
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/x-www-form-urlencoded |
Body中放置请求参数,参数如下:
| 参数 | 是否必选 | 类型 | 可选值范围 | 说明 |
|---|---|---|---|---|
| image | 和url二选一 | string | - | 图像数据,base64编码 |
| url | 和image二选一 | string | - | 图片完整URL |
| language_type | false | string | CHN_ENG、ENG、 POR、FRE、 GER、ITA、 SPA、RUS、 JAP、KOR |
识别语言类型,默认为CHN_ENG。可选值包括: - CHN_ENG:中英文混合; - ENG:英文; - POR:葡萄牙语; - FRE:法语; - GER:德语; - ITA:意大利语; - SPA:西班牙语; - RUS:俄语; - JAP:日语; - KOR:韩语 |
| detect_direction | false | string | true、false | 是否检测图像朝向,默认不检测,即:false。 |
| detect_language | false | string | true、false | 是否检测语言,默认不检测。当前支持(中文、英语、日语、韩语) |
| probability | false | string | true、false | 是否返回识别结果中每一行的置信度 |
返回参数如下:
| 字段 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| direction | 否 | int32 |
图像方向,当detect_direction=true时存在。 |
| log_id | 是 | uint64 | 唯一的log id,用于问题定位 |
| words_result | 是 | array() | 识别结果数组 |
| words_result_num | 是 | uint32 | 识别结果数,表示words_result的元素个数 |
| +words | 否 | string | 识别结果字符串 |
| probability | 否 | object | 识别结果中每一行的置信度值 |
| language | false | int32 | 当detect_language=true时存在 |
于是,我们可以构造post请求,具体的参数格式参照api的要求。得出的函数如下:
def get_ocr(token,img64):
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
params = {"image": img64}
url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token=' + token
res = requests.post(url, data=params, headers=headers)
try:
num = res.json()["words_result_num"]
text = res.json()["words_result"]
except:
print("Json ERR")
else:
print("识别到结果共计: " + str(num))
for i in text:
print(i['words'])
返回结果同样是json数据,我们取其中的字段数[words_result_num]和具体字段[words_result]即可。
实现效果:
要识别的图:

识别结果:

哈哈,通用版本貌似精度不是很高?没关系,百度okr还提供了高精度识别、含位置的高精度识别等等,换个高精度url试一试:

卧槽?果然高精度识别更吊一些~!
其次,百度还提供了针对不同场景的识别:手写文字识别、身份证、银行卡、营业执照、护照、名片、户口本等等,各位老哥自己可以试试。如果有机会,博主想集成一个网页识别到博客里,这样就可以更方便的操作了。
(插句题外话,关于python的枚举代码)
from enum import IntEnum
class OCR_TYPE(IntEnum):
general_basic =1, #通用文字识别
accurate_basic =2, #通用文字识别(高精度版)
general_enhanced =3, #通用文字识别(含生僻字版)
handwriting =4, #手写文字识别
idcard =5, #身份证识别
bankcard =6, #银行卡识别
if __name__ == '__main__':
for i in OCR_TYPE:
print(i.name,'->',i.value)
print(OCR_TYPE['handwriting'].value)
最后附上完整源码,改下clientID 和 clientKey 即可。
# coding:utf-8
import requests
import base64
#修改为你申请的app参数
AppKey = 'HGXnQTTvk3mTeP1Fk3mOgdbI'
SecretKey = '4e7U2tOmEAhKfqirIKMgEzbOy1ChlOsK'
def get_token():
token_url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + AppKey+ '&client_secret=' + SecretKey
try:
token_res = requests.get(token_url)
except:
return 'error'
else:
try:
print(token_res.text)
res = token_res.json()["access_token"]
except:
return 'error'
else:
return res
def get_pic64():
try:
with open ('./test.png','rb') as pic:
img64 = base64.b64encode(pic.read())
except:
return 'error'
else:
return img64
def get_ocr(token,img64):
print(token)
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
params = {"image": img64}
#通用识别版本
#url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token=' + token
#高精度识别版本
url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic?access_token=' + token
res = requests.post(url, data=params, headers=headers)
try:
num = res.json()["words_result_num"]
text = res.json()["words_result"]
except:
print("Json ERR")
else:
print("识别到结果共计: " + str(num))
for i in text:
print(i['words'])
if __name__ == '__main__':
token = get_token()
if (token == 'error'):
print("Get token Err!")
exit(0)
img64 = get_pic64()
if (token == 'error'):
print("Get img Err!")
exit(0)
get_ocr(token, img64)
最后,博主自己基于百度OCR的开发的图片文字提取工具,可识别普通文本、手写文本、身份证、银行卡、护照、营业执照、车牌等。链接:https://www.jerrycoding.com/tool/ocr-ui


